
This article discusses some of the foundational components of how Machine Learning is leveraged as part of our Human Data Platform.
Overview
Machine Learning (ML), Data Science, and Artificial Intelligence (AI) are commonplace terms used in the marketing of products and services - but what do they mean, and how do they relate to our Human Data Platform?
Though these terms see frequent use, they defy precise definitions. Depending on who is talking, in what context, and when, any one of these terms might be used to describe a particular technology use case. The common thread is that all three terms concern the use of computational tools to process and extract meaning from data. The Venn diagram below captures a common (though by no means universal) opinion on how these concepts relate to each other.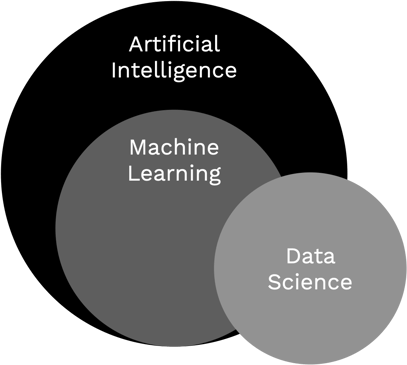
What is machine learning?
An Internet search will yield a vibrant discussion of these three subject areas, but for our purposes, the following synopsis is deemed sufficient:
- Artificial Intelligence: the use of computers to emulate human intelligence capabilities
- Machine Learning: the use of computation to automatically learn from experience captured in data
- Data Science: a set of tools used to process, describe, and transform data in order to extract meaning
In describing what we do at Sparta Science, we most frequently use Machine Learning terminology because the software tools and algorithms we use are most frequently characterized in that way. These tools include the use of neural networks (referred to as Deep Learning) in addition to several others.
Why is ML needed?
Artificial intelligence and machine learning tools have existed for decades, but the use of machine learning has grown exponentially in recent years. This is largely due to a combination of exponential improvements in computer processing capabilities and an exponential increase in the amount of data being generated. We now have more data than ever, but luckily we also have more tools and computing power to analyze that data.
There has been an explosion in recent years in the velocity, variety, and volume of human health and performance data (or human data) that is being generated. What once was scarce, static, and specific has matured to be abundant, dynamic, and comprehensive. The abundance and complexity of this data have outgrown traditional analytics and modeling techniques, requiring more sophisticated tools for the analysis of human data. This has paved the way for organizations to leverage human data using machine learning techniques to create useful and actionable insights that other industries have gleaned from this innovative field.
Check out our peer-reviewed Clinical Commentary entitled The Use of Big Data to Improve Human Health: How Experience From other Industries Will Shape the Future published in the International Journal of Sports Physical Therapy.
How does Sparta Science use Machine Learning?
The specific terminology matters far less than what we do. In the case of our human data platform (HDP), there are four primary components of our use of machine learning.
- Feature Extraction or Learning: transforms high-frequency time series data into differentiating features (or biomarkers) that characterize a person’s status at a particular time
- Prediction Models: take sets of features (or biomarkers) as inputs and transform them into output assessments (e.g., risk or performance capabilities) or recommendations (e.g., activity programs or things to avoid)
- Dimension Reduction: produce reduced sets of independent biomarkers from base sets that are highly reliable utilizing a combination of optimization and component analysis techniques
- Cluster Analysis: identify groupings and biomarker patterns within populations of individuals utilizing unsupervised learning techniques (e.g., movement strategies)
Feature Learning
When a user executes a single scan test such as a Balance or Jump Scan, the Sparta Scan Kit collects on the order of 1 million measurements. The goal of Feature Learning is to transform those million measurements into a form that captures the essential pattern or signature in that user’s movement.
There are two approaches to extracting features from the time series data:
- Physics-driven: Use biomechanics concepts to identify specific characteristics of force-time series data that could be useful features. Then, use numerical analysis to calculate these features from the time series data.
- Data-driven: Use machine learning techniques to extract features (or biomarkers) directly from the 1000 Hz force-time series data through pattern recognition
Prediction Models
One of the key components of machine learning is to use incoming data to predict the likelihood of a future outcome. It is a prerequisite to have large amounts of data to ensure accurate predictions can be made. The data scientists use extracted features to build and use Prediction Models. These models are built using supervised and semi-supervised learning techniques that combine feature data with injury, performance, and activity data. These models aim to transform the biomarkers extracted from scan results into assessments of risk (e.g., relative injury risk, fall risk) and performance, as well as recommendations that guide users' actions to improve their health, performance, and readiness.
Dimension Reduction
Through featuring learning, biomarkers are extracted from high-frequency time-series data which are further reduced and optimized. Component analysis techniques are utilized to decrease biomarker redundancy and identify primary biomarkers that are independent (e.g., represent different movement capabilities or functions) and highly reliable (i.e., results are consistent from test to test). The aim of dimension reduction is to produce biomarkers that provide utility (i.e., are reliable and meaningful measures) in clinical and operational environments.
Cluster Analysis
Unsupervised learning techniques can be leveraged for many different types of clustering methods, which group objects (or individuals) by similarity based on one or more specific features or biomarkers. Clustering can enable the identification of unique groups and subgroups of individuals within populations based on the complex interaction of biomarkers.
Other Benefits of ML
Accuracy and Reliability of Data Collection
Another critical use of ML in the context of feature learning is ensuring the collected data's integrity or quality. Though the scan tests are relatively simple and force plates are generally reliable, things can go wrong in ways that can invalidate the data, e.g.:
- Users can incorrectly execute a scan test - step off the plate prematurely, remove clothing mid-test, fail to follow an instruction
- Hardware/setup issues - uneven surfaces where a foot is off the ground, weight calibration issues, potential sensor errors
Efficiency, Simplicity, and Practicality
Machine-learning models are utilized consistently in our Product Research and Development stages to ensure that the data collection process is practical and quick and that the visualization and interpretation of data are simple and intuitive. For example, different unsupervised clustering models are utilized to help identify natural groupings of data as well as data redundancies that allow our platform and Customer Success team to surface only the most critical information. The increase in data collection capabilities can be overwhelming, leading to paralysis analysis because of the volume of data that exists. Our modeling allows the ability to surface the minimum set of meaningful data points and references that can provide insight and information and drive intervention or action. Additionally, these models are deployed directly into our software and run in real time on our devices. This enables there to be zero lag time from data collection, through data analysis, and into data interpretation.
Continuous Future Improvement
The Sparta Science approach facilitates continuous improvement and expansion of ML-based capabilities over time as more data is collected. Our platform allows for frequent updates and the addition of models over time. An update of models occurs when the platform determines that new models that incorporate more recent data outperform their predecessors (relevant to both Feature Learning and Prediction models). The addition of models can take several forms, including:
- New feature/biomarker discovery
- Expanded Prediction Model functional granularity:
- Injury type-specific models
- Performance characteristic-specific models
- Activity-type specific recommendations
- Population/Group-specific models: As sufficient quantities of data is collected for specific groups, the possibility exists to create models specific to that group that may provide additional insights.
- Longitudinal Prediction Models: As data is collected over time for individuals, the identification of patterns of change over time frames on the order of weeks becomes possible.
Additional Resources:
- Clinical Commentary: The Use of Big Data to Improve Human Health: How Experience From other Industries Will Shape the Future
- Research Summary: Phenotype clustering in health care: A narrative review for clinicians
- Research Summary: Sports Medicine and Artificial Intelligence: A Primer